CS 111 Lecture 4 - Virtualizable Processors
Authored by: Jameel Al-Aziz, Eyal Blum, and Yenan Lin
Table of Contents
- The Problem and the Goal
- Building A Wall
- What Needs Protection?
- Access to Registers
- Context Switching
- Notes
The Problem and the Goal
Once we have an OS Kernel, we want to be able to run applications in our OS. However, some applications can be unsafe and untrusted. If applications had full access to the kernel and processor, they could do whatever they wanted. We want to be able to segregate applications from the OS Kernel and control what the application is able to do.
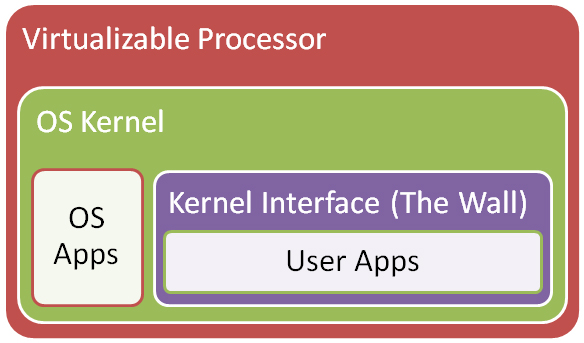
Virtualization Intefaces
Building A Wall
There are two ways to build this "wall" (or interface) between the kernel and the rest of the system:
- Function Calls
- Protected Transfer of Control (What we want.)
- How does the x86 do it?
Function Calls
Function calls are the simplest way to implement the interface between the kernel and applications. An application just calls the kernel to perform special operations. This approach is common on stripped-down machines, such as embedded systems.
Unfortunately, this approach has several disadvantages:
- Once applications get big and complicated, they can easily cause system-wide crashes (affectionately known as the BSOD). Basically, a small bug in one application can take down the entire system.
- If we allow third-party applications to run on our system, malicious programs can easily take over the system.
- We cannot keep secrets. The callee (the kernel in this case) cannot do anything the caller (the application) couldn’t already do. Basically, the callee (kernel) has no special powers. (See Note 1 for details)
Protected Transfer of Control
Protected transfer of control is based on a simple concept: Take everything the hardware can do, and divide it into two pieces:
- What operations are OKAY for ordinary apps to do? (e.g. add, subtract, etc.)
- What operations are NOT OKAY for ordinary apps to do? (i.e. privileged instructions that should be reserved for the kernel)
To implement such behavior, our code needs to know whether we are in kernel or in application code. We can provide such a feature by using a “privilege bit”. Ordinary applications run unprivileged and have to ask the kernel to perform privileged instructions. They ask the kernel to do so by issuing a special instruction that:
- Enables the privilege bit
- Changes the Instruction Pointer to the Kernel (i.e. transfers control to the Kernel).
The Kernel then performs the privileged instruction, returns the result (if necessary), and clears the privilege bit. (See Note 2)
How does the x86 do it?
When designing a system, we don’t the processor to halt on an unsafe system call. In the x86 line of processors, instead of halting, the hardware traps and transfers control to the kernel. The kernel can then decide what to do about the system call (execute it or block it). By convention, the INT (interrupt) instruction is used to legitimately request a privileged instruction to be run.
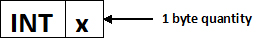
Calling the INT instruction
The hardware contains a special table (known as the interrupt address table or interrupt descriptor table) in memory that holds 256 entries. Each entry contains the address that the Instruction Pointer (IP) should be set to when a particular interrupt occurs and a value determining whether the privilege bit should be on or off.
| Trap Mechanism | ||
|---|---|---|
| Pushes: (Onto Kernel Stack) |
ss esp eflags cs eip error cell |
Stack Segment* Stack Point* Code Segment Instruction Pointer |
| Then: | reti | Return from interrupt |
*Top of user's stack
There are some minor problems with this implementation. Luckily, the problems can easily be avoided. The problems and their particular solutions are outlined below:
| Problem | Solution |
|---|---|
| Kernel can be buggy and may not reset the privilege bit | Don't write buggy code! |
| Stack can be full, we may overwrite something else! | The Kernel stack is usually kept somewhere else |
| We may run out of entries in the descriptor table | Use a register (e.g. eax) to determine the system call value |
The system can be modeled as several applications that run atop both hardware and the kernel simultaneously, calling the kernel mainly to execute privileged instructions.
The beauty of this design is that it implements both abstraction and enforcement. Furthermore, each application may see a (slightly) different virtual machine depending on its needs (or as the kernel sees fit).
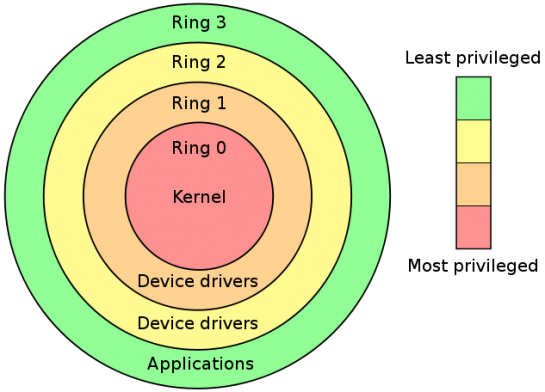
Protection Rings of the x86 line of processors. Source: http://fawzi.wordpress.com/2009/05/
What Needs Protection?
With this implementation, the question arises: what resources should be protected? An easy solution would be to simply protect all the resources. Unfortunately, calling protected resources incurs a lot of overhead. Therefore protecting all resources will cause the system to slow down significantly. We must only protect resources which may cause stability or security issues.
The ALU (Arithmetic Logic Unit) obviously does not need to be protected and, by convention, all code has full access to the ALU, always! How about registers? User applications must of access to their own registers, so we must grant full access to these registers. These registers include eax, ebx, ecx, edx, etc. Full access must also be granted to both the stack and instruction pointers, otherwise an application would not be able to efficiently use the stack or run any instructions (See Note 3). However, privileged access is required for “security relevant” registers (e.g. the privileged bit register).
The processor cache is intended to invisible; any attempts to access it will be deferred to primary memory. Primary memory (RAM) is a special case. Some regions need protection (e.g. kernel-related regions) and should trap if written to or read from, while other regions do not and should have full speed access. However, hardware designers don’t know where these protected regions are. Defining static protected regions is infeasible as some OSes require more protected memory, while others require less. To overcome this issue, a page table is used. The kernel stores the page table in protected memory and tells the hardware where it can be found.
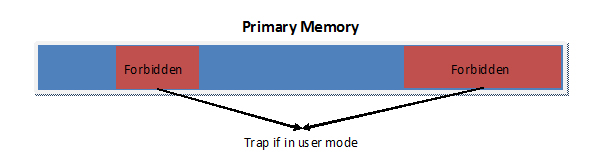
Forbidden zones in Primary Memory
Since I/O devices are slow and not commonly accessed, the common approach is to require kernel privileges for all access. Some devices, such as video devices, are special cases and are granted full speed access. Usually, this is implemented using memory mappings through the page table.
All the previous resources dealt with space. How about time? Time also needs to be managed. We do not want one application to hog all the system resources. The x86 approach to this problem is to insert interrupt instructions into the instruction stream of all processes, unless otherwise specified. These clock interrupts occur every 10ms, but are adjustable. (See Note 4)
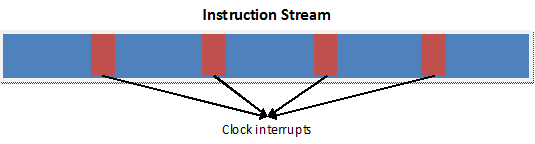
Instruction Stream with Clock Interrupts
Access to Registers
As mentioned earlier, applications have full access to all user registers. This means that applications can overwrite each other’s registers. Or, each application can have its own set of virtual unprivileged registers. In fact, most current OSes use virtual registers to help secure concurrent processes. Virtual registers are not implemented in hardware. The OS must help by storing and loading the virtual registers.
Currently running applications use the hardware registers (e.g. eax, eip, esp, etc.). This makes sense as access to the hardware registers incur little overhead. When another application is run, the OS stores a copy of the other application’s registers in a special table that is kept in a privileged area. This table is called the Process Descriptor Table. Each row represents a process descriptor for an application that’s trying run.
| Apps that want to run | eax | esp | eip | other registers... | privileged registers... | I/O.... |
|---|---|---|---|---|---|---|
| 1 | Contents of virtual registers of application 1 | |||||
| 2* | ? | ? | ? | ? | ? | |
| ... | Contents of virtual registers of applications 2 through n-1 | |||||
| n | Contents of virtual registers of application n | |||||
*Currently running process. Info in table is 'garbage'. (? = garbage)
Context Switching (See Note 5)
Context switching is the idea of switching through applications at certain time intervals to simulate concurrent processes. Application context switches are performed in the kernel. An overall process of context switching can be described as follows:
- Stop running one application (App 2).
- Store the state of the unprivileged registers for the application (App 2).
- Restore the state of the unprivileged registers for the next application (App 4).
- Start or resume running the next application (App 4).
Context switching incurs some overhead; hence, some systems have fewer registers. A solution to help with this overhead is known as lazy context switching. Lazy context switching involves saving only commonly used registers and then trapping if an application tries to access less-used registers that were not saved. Furthermore, when kernel code is running, a common trick is to only save the registers that the kernel knows will change. Even though context switching is relatively fast, we want it to reduce the overhead as much as possible as the combined overhead may be significant (e.g. a 1ms context switch can result in a loss of almost 10% of machine time).
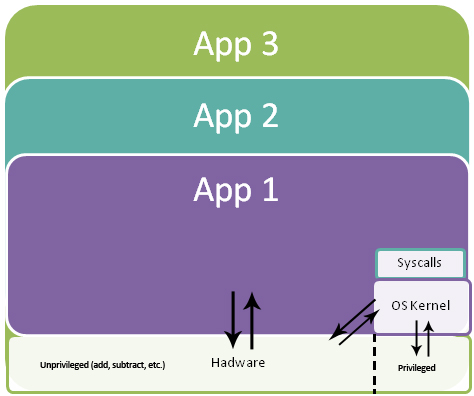
Application Virualization and Abstraction (The final product)
Notes
- If our Operating System used function calls as an interface, how could applications access these calls without going through the Kernel? Simply, the caller can just copy the code the callee (kernel) is running and run it later by themselves.
- Most of the CPU cycles are used by the “application code” part of hardware, only some instructions lie in the “kernel code” part.
- Although the use may set the IP to any value, the hardware interrupts if a program tries to run something it shouldn’t.
- The clock interrupts are inserted by the processor and an individual process cannot predict and has no control over when and where the interrupt will occur.
- Concurrent processes can mess with each other (i.e. rm –rf) while they are running. Unfortunately, there is no general solution to this problem.